Union Find の計算量を解説する。
目次
二項木とは
いくつかの種類の Union Find において最悪ケースを与える二項木 \(B_k\) を最初に紹介する。
二項木を
- \(B_0\) は 1 頂点からなる根付き木
- \(B_{k+1}\) は、根の子をそれぞれ新たな根とする部分木が \(B_0,B_1,\ldots,B_{k}\) である根付き木
と定義する。\(B_0,B_1,B_2,B_3,B_4\)を図示すると下図のようになる。

帰納法から二項木 \(B_k\) は頂点数 \(2^k\) 、高さ \(k\) である。
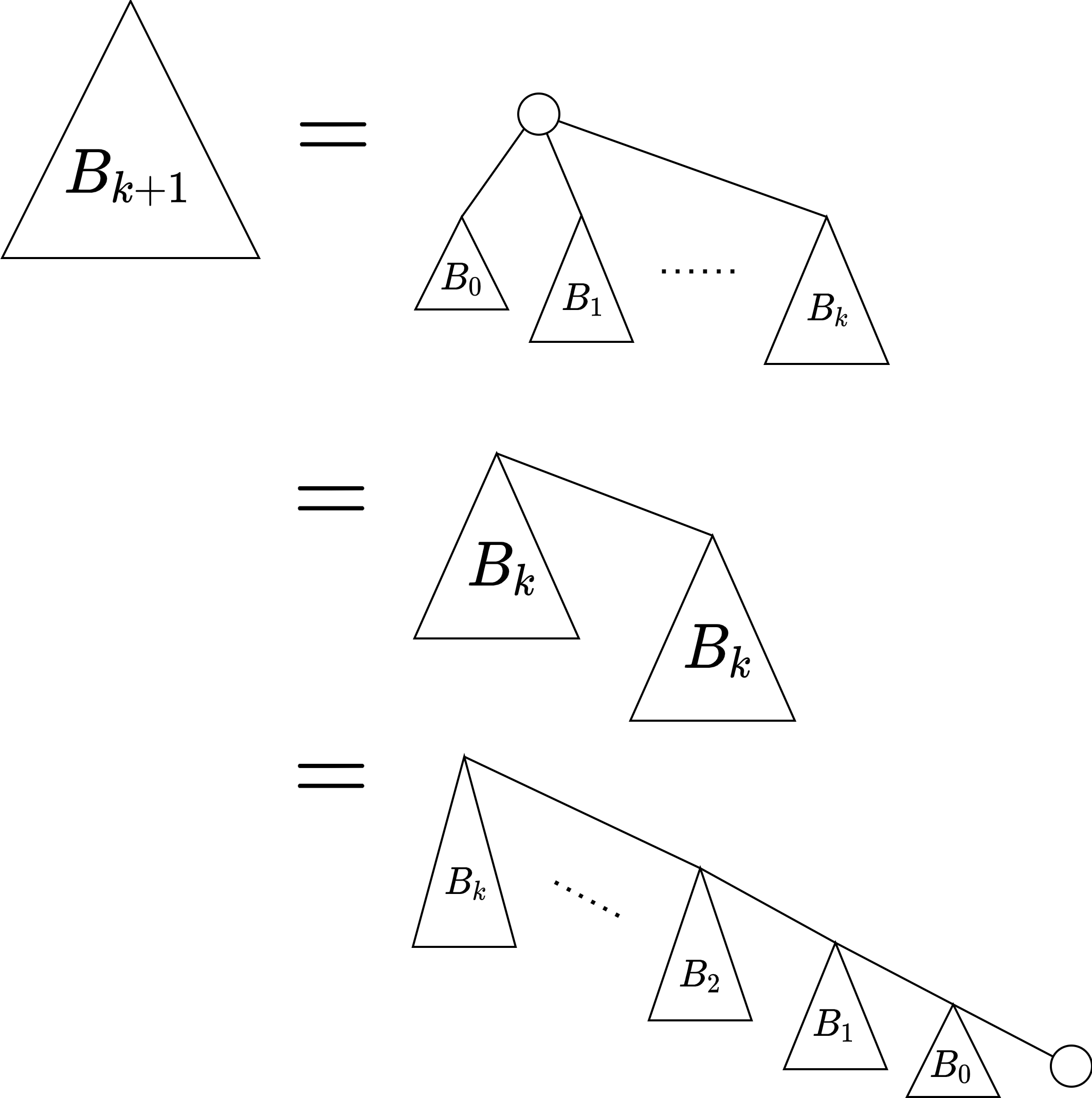
帰納法から \(B_{k+1}\) の構成方法は図の通り 3 つある。 union by rank, union by size いずれでも \(B_k\) と \(B_k\) を Union すると \(B_{k+1}\) ができるから、Union Find の \(2^{k}\) 回の合併で \(B_k\) を作りだすことができる。
union by size の計算量
union by size とは、根付き木 A, B を union するとき、頂点数の小さい方の木をもう一方の木の根の子とする方法である。
その構成方法から \(2\mathrm{size}(u) \leq \mathrm{size}(\mathrm{parent}(u))\) が成り立つ。従って \(O(\log{n})\) である。二項木が最悪ケースを与える。
union by rank の計算量
union by rank とは、根付き木 A, B を Union するとき、rank の小さい方の木をもう一方の木の根の子とする方法である。rank は(経路圧縮しないときの)木の高さとして定義する。
まず、ランク \(r\) 以上の頂点を根とする部分木のサイズは \(2^r\) 以上であることを帰納法で示す。
(i) r = 0 のとき、木が 1 頂点からなるから成立する。
(ii) r = k で成立を仮定する。 rank k + 1 の木は形成過程で rank k の木同士を Union する。帰納法の仮定からランク k の木は頂点数 \(2^k\) 以上だから、ランク k + 1 の木の頂点数は \(2^{k+1}\) 以上である。従って r = k + 1 で成立。以上 (i), (ii) から帰納法により任意の r について成立する。
ランク \(r\) の木のサイズについて \(2^r \leq n\) より \(r \leq \lfloor \log_2 n \rfloor \)。ランクは高さと一致していたから find クエリと union クエリは共に \(O(\log n)\) となる。二項木が最悪ケースを与える。
経路圧縮の計算量解析
経路圧縮(path compression) では Union が \(O(1)\)、find がならし \(O(\log n)\) であることを示す。path halving, splitting は同じように解析できるので扱わない。
分割統治による証明
経路圧縮を無視したとき、最終的にできる木を考える。上下に \(n/2\) 頂点ずつに分けて、それぞれ \(A, B\) と置く。\(A\) は木、\(B\) は森になる。n 元集合の union find に対して m 回の union / find を行った時の計算量を \(T(n, m)\) と置く。\(T(n, m)\) のうち、A の頂点同士を端点に持つ辺が find のパスに含まれるのは \(T(n/2, n)+O(m)\) 回。B の頂点に対しても同様。A と B の頂点を両端点に持つ辺は 各 find のパスに高々 1 回しか含まれず \(O(m)\) 回。\(\sum_i T\left(n_i, m_i\right) \leq T\left(\sum_i n_i, \sum_i m_i\right)\) より \(B\) の各連結成分ごとの計算量をまとめ上げると \(T(n, n) \leq 2T(n/2, m)+O(m)\) より \(T(n, m)=O(m \log(n))\) である。
ポテンシャルを使った証明
時刻 \(t\) における頂点 \(i\) の部分木のサイズを \(\sigma_i(t)\)、ポテンシャル関数を \(\Phi(t):=4\sum_{i=1}^n \log \sigma_i(t)\) と置く。\(0 \leq \Phi(t) \leq 4n\log n\) かつ \(\Phi(0)=0\) である。
union では繋ぎ合わせる根のポテンシャルの寄与しか変化せず、一回当たり \(O(\log n)\) しか増加しない。union では内部で 2 回 find を行うから、union でのポテンシャルの増分は find に割り当てればよい。
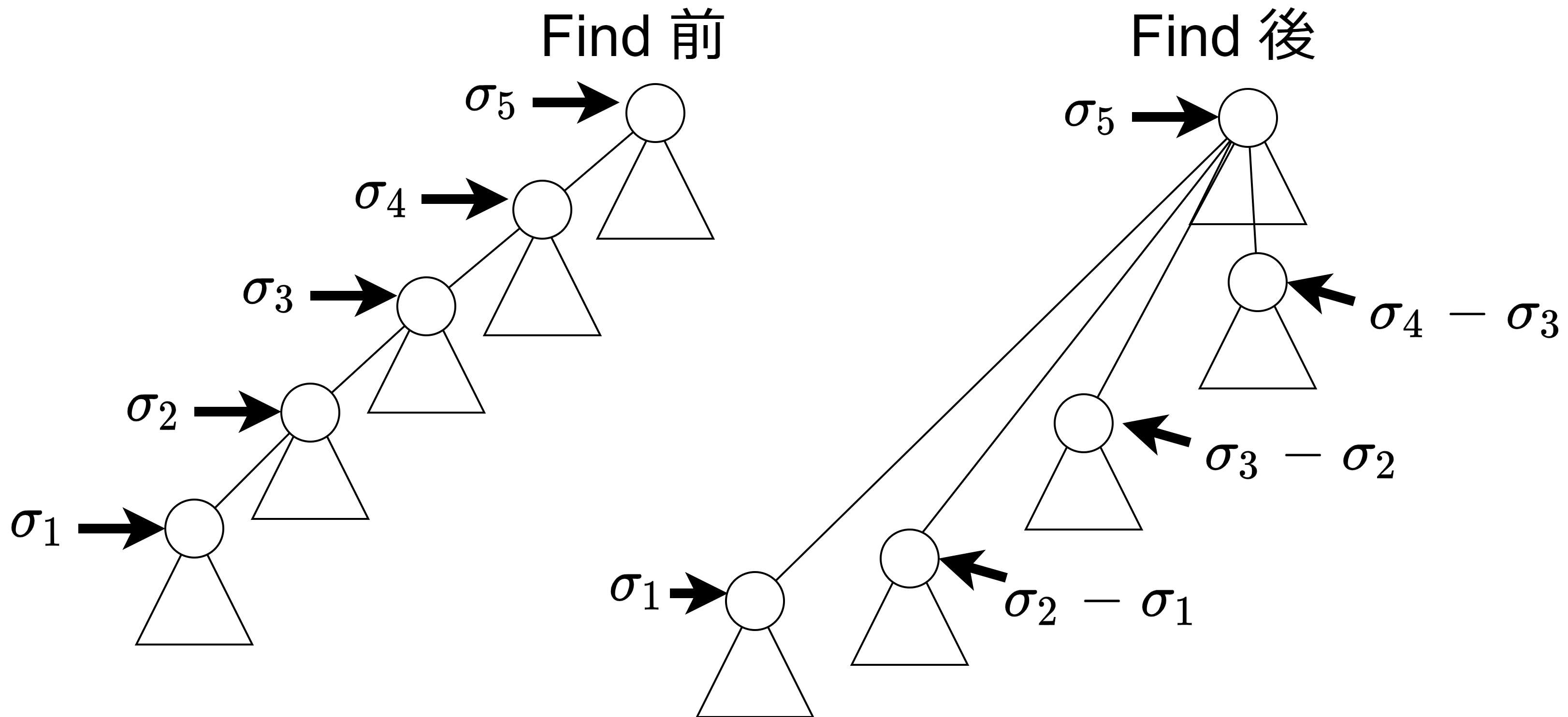
時刻 \(t\) の find において辿るパス上の頂点を根から遠い順に \(\sigma_1,\sigma_2,\ldots,\sigma_k\) と置く(上図は k=5 の場合)。find には根を見つけるのに \(k\) ステップ、根を繋ぎ替えるのに \(k-1\) ステップの合計 \(2k-1\) ステップかかる。ポテンシャルの変化量は
$$
\begin{align}
H(t)-H(t-1)
=&4\sum_{i=2}^{k-1} \left(\log(\sigma_{i}-\sigma_{i-1})-\log\sigma_{i}\right)\\
=&4\sum_{i=2}^{k-1} \log\left(1-\frac{\sigma_{i-1}}{\sigma_i}\right)\\
\leq & – 4\sum_{i=2}^{k-1} \frac{\sigma_{i-1}}{\sigma_i}\
\end{align}
$$
で抑えられる(最後の不等号 \(\log(1-x) \leq -x\) は原点での接線より)。\(\frac{\sigma_{i}}{\sigma_{i+1}} \leq 1/2\)なる \(i\) が \(m\) 個あるとする。\(1 \leq \sigma_1 < \sigma_2 < \ldots < \sigma_k \leq n\) だから、\(2^m \leq \sigma_k \leq n\) となり、\(m \leq \log n\)。従って
\(-4\sum_{i=2}^{k-1} \frac{\sigma_{i-1}}{\sigma_i} < -4\cdot\frac{1}{2}(k-2-m) < -2k+4+4\log n\)
より \(H(t)-H(t-1)+2k-1=O(\log n)\) となる。\begin{align}
&\sum_t (H(t) – H(t-1) + \text{(complexity of each find)}) \\
=& H(t_{\text{last}}) – H(0) + (\text{complexity of find}) \\
=& O(n\log n) + (\text{complexity of find})
\end{align}
より find はならし \(O(\log n)\) である。
Path Compression の最悪ケース
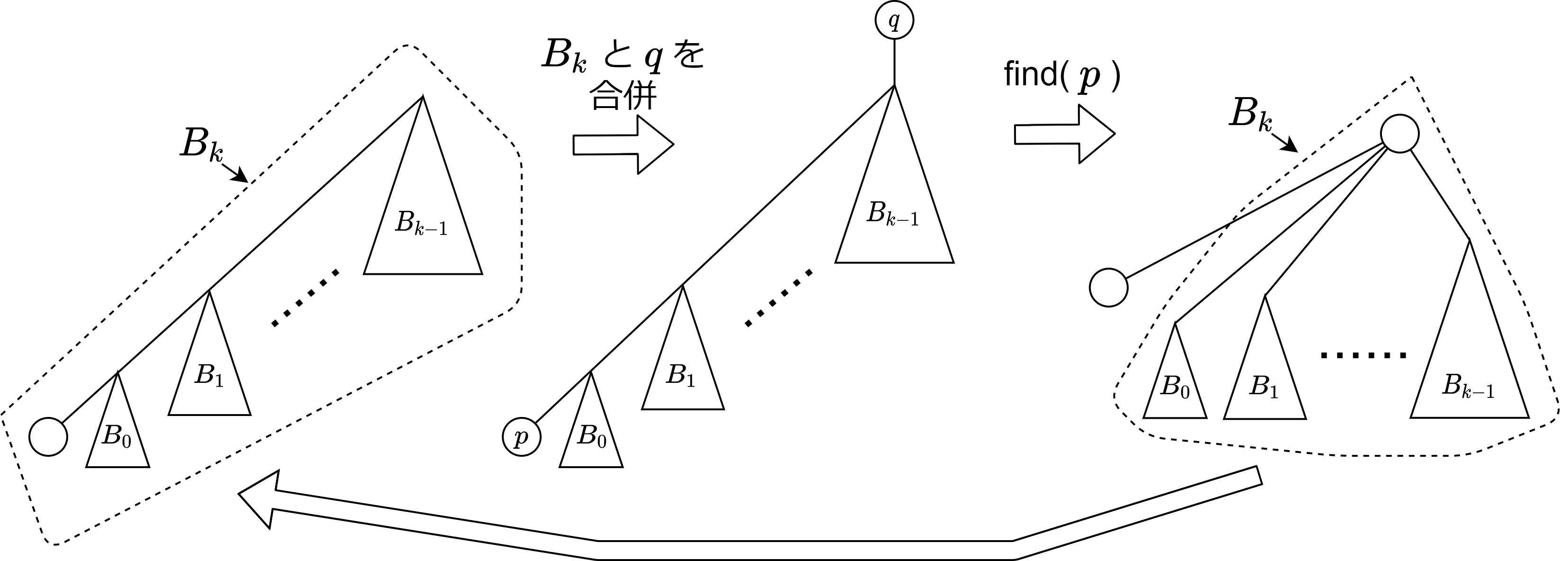
\(k=\Theta(\log(n))\) として、画像の操作を \(\Theta(n)\) 回だけ繰り返すと union と find がならし \(\Theta(\log n)\) となる。
union by rank, size と経路圧縮の組み合わせ
union by rank (または by size) と経路圧縮を組み合わせたとき、クエリ当りの計算量がアッカーマンの逆関数 \(O(\alpha(n))\) となることが知られている。まずは、評価を弱めて iterated logarithm \(O(\log^*(n))\) で抑えられることを示そう[4, 6]。iterated logarithm は $$ \log^* x :=
\begin{cases}
0 & \mbox{if } x \le 1; \\
1 + \log^*(\log x) & \mbox{if } x > 1
\end{cases}$$ で定義される。\(x \in [\underbrace{b^{b^{\cdot^{\cdot^{b}}}}}_{y-1個}, \underbrace{b^{b^{\cdot^{\cdot^{b}}}}}_{y個})\) に対して \(\log_b^*(x)=y\) である。
次の定理が union by rank のときに成り立つことは、「union by rank の計算量」の節で示した。union by size の場合について示す。
このとき、頂点の個数は葉から遠いほど指数関数的に抑えられ、次の定理が成り立つ。
例えば、完全2分木がこの条件を満たす。経路圧縮 の最悪計算量の例はrankが \(\Theta(n)\) あるので満たさない。長さ \(\log(n)\) のパスが \(n/\log(n)\) 本だけ根に接続した木も駄目である。\(n / 2^r ≥ 1 \Leftrightarrow r ≤ \log_2(n)\) よりこの結果は木のrankが \(O(\log(n))\) であることを包含している。しかし、それだけでは後の計算量解析には不十分である。というのも、経路圧縮の最悪計算量は高さ \(\log(n)\) の二項木で構成できたが、\(n / \log(n)\) 個の高さ \(\log\log(n)\) の二項木において同様のことをすると、rankを\(O(\log(n))\)で抑えながら計算量が \(\log\log(n)\) のケースを作れるからである。そして、rank \(O(\log(n))\) の木ではこれが最悪計算量であることが示せる。頂点の個数が葉から遠いほど指数関数的に減少することが\(O(\alpha(n))\)には必要である。
定理を証明する。
証明2(by rank のみ):rank k + 1 の木を作るには rank k の木が二つ必要なため。
余談:部分木のサイズ \(2^{s + 1} > x ≥ 2^s\) の頂点数が高々 \(n / 2^s\) でも後の証明は回ると思う(by size だと成り立つ。by rank で成り立つかは確かめていない)。
最終的に全ての頂点が union によって連結になると仮定しても、計算量評価の一般性を失わない。find によって、与えられた頂点から根まで辿るパスの辺の数を評価すれば良い。
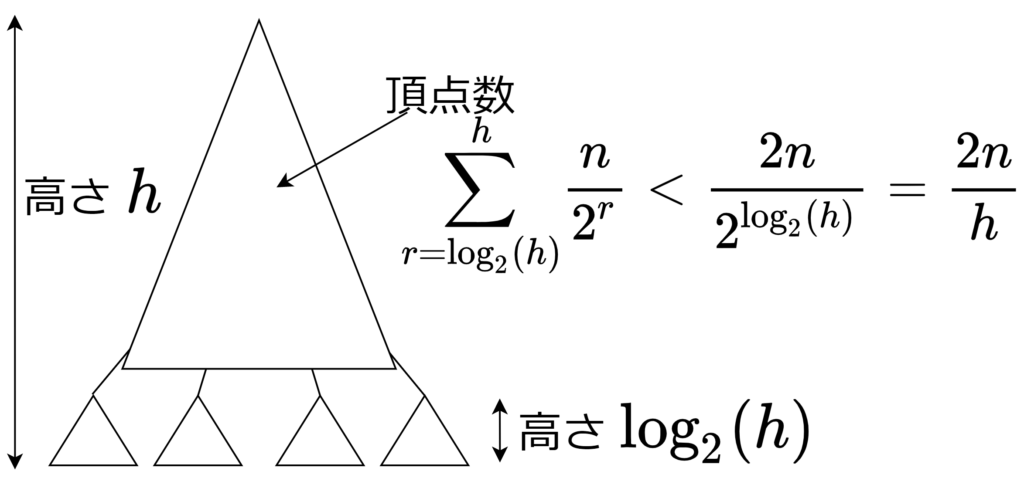
ランク \(h\) の森に対して、ランク \(\log_2(h)\) を境に上下に分割する(下図)。ランク \(\log_2(h)\) 以上の頂点の数は \(\sum_{r=\log_2(h)}^h n/2^r < 2n/h\) で抑えられる。この頂点同士を端点に持つ辺が find のパスに含まれるのは \(O(h(2n/h)) = O(n)\) 回。ランク \(\log_2(h)\) 以上の頂点と未満の頂点を端点に持つ辺は 各find のパスに高々 1 回しか含まれないから、操作全体で \(O(n)\) 個。ランク \(\log_2(h)\) 未満の森に対して分割統治を繰り返す。分割統治は \(O(\log^*(h))\) 回繰り返せば終了するので、全体で \(O(n\log^*(h))\) 時間。
そして\(\alpha(n)\)へ………
頂点数 \(n\)、ランク \(h\) の木に対して \(n\) 回の find を行った時の計算量を \(T(n, h)\) とする。ランク \(s-1\) 以上の頂点と未満の頂点で上下に分割すると、\(O(n \log^*(n))\) のときと同様にして、計算量は
$$T(n, h) \leq T(n/2^{s-2},h) + n + T(n, s)$$となる。\(T(n, h) \leq cng(h)\) とすると、\(s=\log_2 (g(h))\) とすることで
\begin{align}
T(n, h) &\leq T(4n/g(h),h) + n + T(n, \log_2 g(h))) \\
&= 4cn + n + T(n, \log_2 g(h)) \\
&= (4c+1)n(\log_2 g)^*(h)
\end{align}である。
- \(T(n, h) \leq cn^2\) より \(T(n, h) \leq (4c+1)n \log_2(n)\)
- \(T(n, h) \leq (4c+1)n \log_2 n\) より \(T(n, h) \leq (4c+2)n (\log_2 \log_2)^* (n)\)
- \(T(n, h) \leq (4c+2)n (\log_2 \log_2)^*(n)\) より \(T(n, h) \leq (4c+3)n (\log_2 (\log_2 \log_2)^*)^* (n)\)
\(g(h) = O(1) \) となるまで \(g \leftarrow (\log_2 g)^*\) を適用する回数は \(O(\alpha(h))\) で抑えられ、このとき \(c = O(\alpha(n))\) であるから \(T(n, h) = O(n \alpha(n))\) である。
findを繰り返したときの計算量
union find で \(\Theta(n\log(n))\) 回 find (union 内部のそれを含む)すると、ならし \(O(1)\) になる。path compression を
無視した仮想的な木は、高さが \(O(\log(n))\) になるから。Gabowらの最小全域有向木問題の高速化に Union Find のオーバーヘッドが掛からない理由がこれだった。
参考文献
- Kevin Wayne 氏の授業スライド
- 図が豊富で分かりやすいです。アルゴリズムの挙動自体が分からないという場合はこちらを見ると良いと思います。
- Alternative path compression techniques. van Leeuwen, J. van der Weide, R. (1977)
- paht halving を提唱した論文。計算量解析の部分を勉強しました。彼らは path halving + link by rank はクエリ当たりの計算量が iterated logarithm \(\Theta(\log^* n) \) だと予想していたようです(実際はアッカーマンの逆関数)。
- Fischer, Michael J. “Efficiency of equivalence algorithms.” Complexity of Computer Computations. Springer, Boston, MA, 1972. 153-167.
- path compression の計算量解析のために二項木を導入した論文。二項木のフラクタルな構造が面白いと思いました。
- Hopcroft, John E., and Jeffrey D. Ullman. “Set merging algorithms.” SIAM Journal on Computing 2.4 (1973): 294-303.
- 計算量が iterated logarithm で抑えられることを示した論文。
- Disjoint-set data structure – Wikipedia
- Seidel, Raimund, and Micha Sharir. “Top-down analysis of path compression.” SIAM Journal on Computing 34.3 (2005): 515-525.
関連記事
- 最悪計算量を最小化したUnion Find
- 永続化したい場合やオンラインで処理したい場合、ならしではなく最悪計算量を最小化した方が良いことがあります。ならし計算量 \(O(\alpha(n))\) の Union Find は、最悪計算量が \(\Theta(\log(n))\) になることがあります。この記事では最悪計算量 \(O(\log(n)/\log\log(n))\) の Union Find を紹介しています。
Comments